
Inception Labs have just released Mercury 2 - their latest diffusion large language model and it’s pretty solid. This goes beyond a technical proof of concept and into the realms of something that is genuinely interesting as well as practically useful.
To my mind, this is the first “prime time” diffusion language model that’s viable for developers. One that is blisteringly fast at text generation and powerful enough to do real work - especially for coding, which I’ll get to in a moment.
Before getting too excited, it’s worth acknowledging that in terms of model performance, Mercury 2 is roughly on par with Gemini 2.5 Flash, Claude 4.5 Haiku or GPT-5 Mini (all in reasoning mode). This isn’t at the absolute leading edge of capabilities, but this is equivalent to second-tier model performance from 9 months ago (mid 2025) which is still incredibly useful across a large number of tasks. Many people use these models in production right now because of the capability-cost trade-off (generally cheaper than SOTA models).
Except, Mercury 2 can be about 10x faster in end-to-end latency - with reported throughput of ~1,000 tok/s on NVIDIA GPUs in Inception’s setup.
Mercury 2 is a strong indication that diffusion can be competitive at useful capability levels and change the latency curve. If this holds true as models get larger, it suggests an architectural path that could unlock a new scaling regime. This is not by making models ‘smarter’ overnight, but by making deliberation and iteration dramatically cheaper.
Bottleneck escape via diffusion
One of the concerns that many in AI research have held is that the serial, next-token decoding used by autoregressive Transformers (eg your favourite chatbot) has a massive limitation at its heart in the form of serial generation.
If I want to generate a response that is 1,000 tokens long, the model needs ~1,000 token-generation steps. As I generate more tokens, the latency scales proportionately to its length.
When you do complex reasoning or Chain of Thought style generation, everything happens sequentially and the longer each step takes to generate, the longer the whole process takes. This is true even if there’s no external latency introduced (eg asking a user a question, looking up a URL, executing a command etc).
Diffusion sidesteps strict token-by-token serial decoding by refining the output in parallel over a small number of denoising steps. This works more like image generation, but instead of diffusing pixels, it iteratively denoises a text representation.
The upshot of this is that in comparative tasks Mercury 2 may take 1-2 seconds to do a task that an equivalent model may take 15-30 seconds to achieve the same output.
This translates into raw speed for a user but for an agent, this could be a huge unlock.
“System 2” at interactive speed
Even with the state-of-the-art models that most developers use every day for coding1, it’s not uncommon for reasoning-enabled runs to burn a lot of internal compute / hidden tokens to figure out how to achieve a task, before pulling together an approach. This can easily take 30-60s.
Even without raising the “intelligence ceiling”, I’m inclined to think about this architecture as an efficiency breakthrough that unlocks or improves many use cases. If a model like Mercury 2 can generate that same level of reasoning in less than 5 seconds, it potentially changes how reasoning could work in “real-time” applications.
This is especially relevant when it comes to things like live agentic processes, and in particular coding agents.
The “Ralph Wiggum” loop on fast forward
Geoff Huntley coined the “Ralph Wiggum” loop (read that link!) to describe building a coding agent that naively just persists at a problem until it gets it right (”I’m helping”).
One of the fascinating things with this type of agentic coding loop is that while a better model is generally desirable, you can still get it to work even with slightly older or locally running open source models. The latest Claude Code, Codex or Gemini CLI are awesome, but in many ways I find it slightly more amazing that you can run Qwen 2.5 and still get good outcomes. They just take longer because the models are less capable.
The key unlock to make this work is validation and feedback. You need some method to guide the agent towards what “correct” looks like so that it persists and ultimately finds its way to success. Without this, you just end up with a random walk, model collapse or achieving a local minimum that it won’t nudge off.
A model that can run at the speed of Mercury 2, coupled with a harness that has good validation and feedback piped into it, could achieve a cycle time far faster than any current SOTA model and get better outcomes via pure brute force alone.
Diffusion doesn’t magically win, however it shifts the bottleneck towards verification and tooling, which is still a huge architectural change. In practice, speed only turns into quality if your harness can validate cheaply and steer reliably; otherwise you just thrash faster.
My rationale for this is that building a feature is kind of like compound interest. More accurately it’s really a compounding decay of error. Intuitively this looks like taking a big first swing at a problem and getting say 50% of the way there, then the next step gets you to 75% then 85% then 90% etc. Each step gets you closer but overall improvement decreases with each step as you remove big issues, then bugs, then smaller bugs, and eventually niche edge cases.
This is where the developer joke of “the last 10% accounts for the other 90% of the time” comes from - the quick wins become slow wins.
What’s interesting is that with a model like Mercury 2, the maths around brute-forcing your way to success with a less capable model fundamentally change.
By way of comparison let’s say a SOTA model gets you 85% improvement per step but Mercury 2 only achieves 15-25% improvement per step.
If each iteration removes r of the remaining error, the score after n iterations is: 1 − (1 − r)^n.
| Model Type | Iterations | Improvement per Step | Final Score2 |
|---|---|---|---|
| SOTA (Frontier top-tier model) | 1 | 85% (Huge leap) | 85.0% |
| Mercury 2 (Conservative) | 10 | 15% (Small fixes) | 80.3% |
| Mercury 2 (Moderate) | 10 | 20% (Decent fixes) | 89.3% |
| Mercury 2 (Aggressive) | 10 | 25% (Good fixes) | 94.4% |
This assumes progress is mostly monotonic under a strong validator; without that, speed just accelerates thrashing.
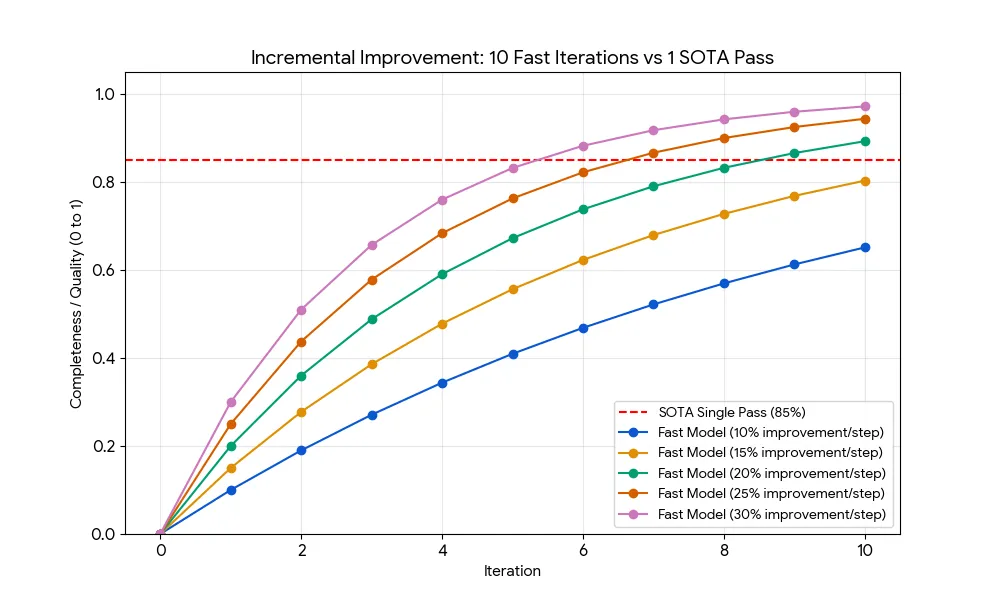
As you can see in the chart above, the fact that the weaker model gets 10x as many iterations in the same time period means it can outperform the SOTA model.
Zeno’s paradox bites hard
The biggest challenge a SOTA model faces against a high velocity, competent one is that diminishing returns rapidly accumulate for the large model. You can see this by extending the time horizon and modelling what most agentic loops actually do: iterate continuously until the task is ‘complete’.
For the point of argument let’s say the model has about 1 minute to get the task complete and closest to “complete” wins. The SOTA model would get about 5 iteration steps (about 12s per turn which is quick but not unreasonable) but the Diffusion model would get about 50 iteration steps (about 1.2s per turn - not unreasonable at 1,000tok/s based on NVIDIA GPUs in Inception’s setup).
We’ll also assume that the SOTA model makes forward progress at about 65% per step which is also not unreasonable given what I’ve seen many models do in practice.
(We’ll ignore validator cost for a moment, but still assume it reliably rejects regressions.)
As you can see in the chart and table below, this lowers the quality bar even further from the first scenario to about a 10% improvement rate per turn. That level of improvement is woeful - basically “poke the code and hope”. Mercury 2 appears comfortably above that threshold in coding-style loops.
| Mercury Improvement Rate | SOTA Final Score (5 turns) | Mercury Final Score (50 turns) | Outcome |
|---|---|---|---|
| 5% (Very “Dumb”) | 99.5% | 92.3% | LOSS |
| 10% (Equivalent) | 99.5% | 99.5% | TIE |
| 20% (Barely competent) | 99.5% | 99.99% | WIN |
| 30% (Mediocre) | 99.5% | 100% | DOMINATION |
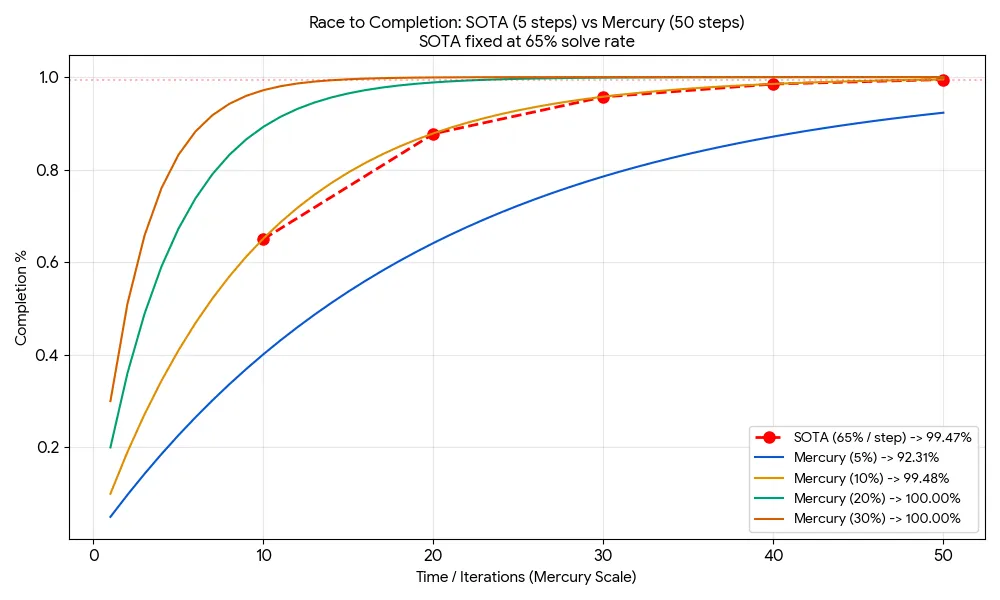
Weaker models can behave even more like the archetypal Ralph Wiggum and achieve success because the speed of their persistence pays off over the equivalent time period.
Put another way. A high velocity, marginally competent model can fail their way to success in the time a SOTA model has time to ponder everything and come up with an answer.
You don’t need to be a genius to fix a bug; you just need to be a persistent worker who can fix one small thing at a time without getting tired.
Hopefully the above bit of napkin-maths shows that there’s a minimal quality threshold that a model has to achieve for this to work, but it’s surprisingly low. Making only 20% incremental progress each step is plenty enough to achieve comparable performance over the same time period as a SOTA model purely based on the number of feedback loops you can generate.
The competence gap isn’t that wide and in some ways it’s better
Mercury 2 is beyond marginally competent. I did a one shot exercise with the following prompt:
Assume a list of images in HTML (unordered list + LI’s that contain
image elements) can you produce for me a simple slideshow carousel
that has next and previous buttons to control the flow of the images.
Use a modern, CSS native approach (eg grid, scrollable etc) and
the smallest amount of JS necessary that is as native as
possible. No frameworks for Javascript (eg React, Vue etc) or CSS
(tailwind, bootstrap etc).It produced some quite capable HTML, which you can try out here.
Stylistically it was a bit different than how I would do it, but given it was produced by what many would deride as now a “third tier” model in approximately 1.5 seconds it generated an output that was on par with what I’d expect from a competent mid-level web developer.
What’s particularly interesting is how some of the code came together and particularly the very tight coupling between the CSS and JS behaviours. From a CSS perspective, it leverages scroll-snap to manage the direction and alignment of the slideshow. In the JS, it doesn’t try to calculate specific pixel coordinates which is brittle, it uses an approximation and nudges the image in the right direction, then lets CSS take over to perfectly align it.
Autoregressive models often over-engineer here. They will compute pixel-perfect JS offsets even when CSS can do the hard work. Generating the structure as a whole (rather than token-by-token) may bias toward tighter cross-file coherence.
In a diffusion approach, this is the sort of holistic approach that can emerge from producing the whole structure at once. In many ways this is closer to how a developer would think about this problem before committing code to solve it.
High-speed verification becomes the new limiter
Anyone using a persistent agentic loop has already started to notice this but if you can loop 10x faster then verification of progress becomes the new bottleneck and limits the pace of the whole system.
Sure, you can pipeline and parallelise parts of this - but the tighter the loop, the more the stopwatch winner becomes whoever can validate and steer fastest.
To date, targeted verification has taken “about a second” but runs on a 15-20s (or longer) cycle (ie ~3-5% of the total time in the cycle). Assuming this stays constant, a cycle taking 1-2s now means 30-50% of that cycle time is taken up by verification.
At this speed it’s a significant system limit, but the order of magnitude cycle count probably still offsets it. But it does mean that cheap, rapid verification methods become even more important in this scenario. This is likely to mean more targeted tests that use some form of change based heuristics (eg test the changes and adjacencies and no more - assume the rest is fine, catch it later).
It could also mean simply pulling the entire verification process out of the loop entirely, running it in parallel at a slower pace and injecting any errors back into the main code agent loop as a “todo list”.
In AI software engineering, we’re seeing a new fundamental limiter appear every 6-9 months that weren’t even theoretical problems because the base of dev wasn’t fast enough. We’ve spent decades getting from quarterly and monthly releases to weekly and daily and now we’re getting getting to hourly (or “minutely??”) in the space of a year.
Diffusion makes decoding cheap. Verification becomes the product. And whoever owns verification, owns the loop.
If you can’t validate quickly, you can’t iterate quickly. This loop only scales with:
- cheap static checks (lint, typecheck, format, fast build)
- targeted tests based on dependency impact
- semantic diffing and invariant checks (API compatibility, schema constraints)
Multiple architectures working together
I’m pretty impressed by Mercury 2 and the potential of Diffusion language models more generally. I’m not sure it kills off autoregressive language models but it could be a good pairing.
I think we land in a situation where we have multiple model architectures running as an ensemble that are flexing up and down as needed. This could be within the context of a single interface that has sub models (similar to Mixture of Experts activation) or the agent harness itself doing some assessment of whether this is a “thinking” task versus a “doing” task and routing accordingly.
This combination of “Deep reasoners” (high latency, high intelligence) and “Fast Diffusers” (low latency, high throughput, verification augmented) could be an unlock that supports greater scaling of looped agent flows where exploration and testing is crucial (such as coding, engineering etc).
It will be interesting to see whether Inception Labs can scale this approach to hit a 90+ GPQA (a reasonable proxy for “this is a model that’s good enough to do a wide range of practical tasks across many domains”) but I’m also curious about what Google Deepmind have got up their sleeves as they have been awfully quiet about diffusion models for the last year given their significant expertise in this space.
This may just be the first chapter in the Diffusion LLM story of 2026.
Update March 11, 2026: Looks like the second chapter has been opened. Andrej Karpathy just dropped Auto Research which, to a large extent proves this thesis. His approach is more like evolutionary algorithms / stochastic hill climbing but it proves that if you have a very quick validation process then your iteration loop shrinks and your overall cycle time improves. Thus you can iterate at pace.